by Jerome Josephraj
Share
Recently I have been working in a large enterprise project, which uses Behavior Driven Development quite heavily. I have always been a huge admirer of BDD and the benefits it can bring to a project. I have personally experienced this in many projects where we have used BDDs. However, as the project scaled, automation becomes brittle and takes longer to run. This blog post is about the mistakes we made in automating BDDs and hopefully the readers will benefit from this by not repeating the mistakes we made.
Tech Stack
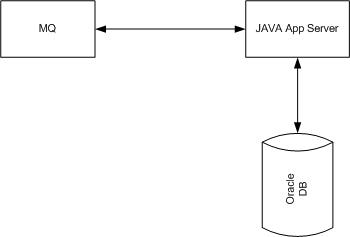
Our tech stack consisted of Spring, Java 8, IBM MQ and Oracle DB and Cucumber for BDD. The following diagram shows a tech stack of our project, which is a quite common integration tech stack used across the industry.
We used Cucumber and Java to implement our BDD solution. All the examples given here are based on my experience with Cucumber.
Common Mistakes
Unfortunately, like any software development approach, the design guidelines for automating BDDs is not well published. While implementing BDDs, we took several wrong design/development decisions, which I would avoid at any cost knowing the impact it will have. By sharing this experience, hopefully the readers will get their design right before embarking upon their journey with BDD as not getting your design right upfront will end up with BDDs that will take longer to run and difficult to change and likely to fail often.
Hard coded test messages
At the start of the project, hard coded xml test messages were used in step definitions as part of message payload. As the test messages grew, it became difficult to manage as any changes to message structure need to be retrofitted into all test messages, which ended up being a really difficult change to manage.
When a message like the one given below is used in one Feature, it is fairly easy to make a change, if required. However, when it is used in multiple feature files then the changes are hard to implement
<?xml version="1.0" encoding="utf-16"?>
<employees>
<employee id="be129">
<firstname>Jane</firstname>
<lastname>Doe</lastname>
<title>Engineer</title>
<division>Materials</division>
<building>327</building>
<room>19</room>
<supervisor>be131</supervisor>
</employee>
</employees>
If a requirement comes along to remove “room” from XML, it is cumbersome to find all XMLs and remove the tag. Nevertheless, it is not as complicated as the following scenario.
<?xml version="1.0" encoding="utf-16"?>
<employees>
<employee id="be129">
<firstname>Jane</firstname>
<lastname>Doe</lastname>
<title>Engineer</title>
<division>Materials</division>
<building>327</building>
<section>
<sectionId>1</sectionId>
<room>19</room>
<section>
<supervisor>be131</supervisor>
</employee>
</employees>
What happens if there is another test XML which has a different requirement and includes “room” inside a tag? Let’s assume a requirement comes along to remove only the “room” tag which is not a child element of “section” tag. If the room tag is removed in all occurrences that would remove the tag under the “section” as well, which is not part of the requirement. I hope you get the drift. As the project expands in complexity, your test data will become a nightmare to manage, if you don’t address it before writing BDDs.
No Parallel Run
Maybe everything would have been different. Hindsight is a mocking bitch for sure. – Author: Tiffany King
Yes, quite a lot would have been different for us if we had started running BDDs in parallel pretty much from day one. Any test suite should give fast feedback to developers. Here is a great article from stackify on why faster feedback is important https://stackify.com/continuous-testing-feedback-loops/
During initial stages of the project, when we had few Feature files , running BDDs serially took only minutes and as a result it didn’t impact our delivery. As the project grew we ended up adding several feature files and as a result Automated BDD test suite were taking longer and longer to run. Finally we ended up with a a run time of more than an hour to run BDD test suite. Though this may not sound as a major issue, the compounded time of all developers running the entire BDD suite may be multiple times per story, resulted in a huge wastage of time. It soon became evident that of all development tasks, running BDDs ended up taking majority of the time.
The prioritisation of running BDDs in parallel came after implementing a large BDD test suite and towards the middle stage of our project, and it became really hard to go back and refactor the code as the stories were in flight and it didn’t give us enough time to address this. In order to get the BDDs to run in parallel we had to:
- Pass unique IDs in each step
- Find a mechanism to pull unique messages from Qs
- Manage database transactions using Unique IDs
- Change all Features to use Unique IDs
- Avoid static variables
Some of the above mentioned issues are explained in following sections in detail
Avoiding Unique IDs
While writing Feature files, we reused IDs between feature files, scenarios and steps. These IDs were used for Database transactions and MQ transactions: That’s any delete/update operation on the database and pulling off the Q should be based on the unique id. This was perfectly fine as long as the test suite ran in parallel and didn’t work when we tried to run test suite serially.
Consider the following two feature files
Feature 1 Feature: Check Employee Status Scenario: Check employee status is "Permanent" Given database doesn't contain employee id "EMP001" And database is populated with employee id as "EMP001" and status as "Permanent" When employee status check api is called to check status of employee id "EMP001" Then response message should contain status as "Permanent" for employee id "EMP001"
Feature 2 Feature: Get Employee designation Scenario: Get employee designation as "System Consultant" Given database doesn't contain employee id "EMP001" And database is populated with employee id as "EMP001" and designation as "System Consultant" When employee designation check api is called to check status of employee id "EMP001" Then response message should contain designation as "System Consultant" for employee id "EMP001"
When we tried to run these two features at the same time, we had data collision as Feature 1 could override Feature 2’s data and vice-versa. In order to get these two features to work both features have to use Unique Ids i.e. EMPxxx and the DB and MQ code have to changed to access unique values. Getting DB to access unique code is fairly a straight forward process, however changing MQ code to access messages based on unique id is the trickiest part.
No Single Responsibility Principle (SRP)
If I have to pick one important development principle that would be SRP. Originally coined by Robert C Martin (Uncle Bob) and hammered home relentlessly over the years. Though we gave lot of attention in rolling out SRP in our development project, in BDD it was completely ignored. As a result we ended up with large monolithic steps and duplicated steps, which resulted in making changes harder and the code became very brittle.
Consider these example features
Feature 1 Feature: Check Employee Status Scenario: Check employee status is "Permanent" Given database doesn't contain employee id "EMP001" And database is populated with employee id as "EMP001" and status as "Permanent" When employee status for "Contractor" is called to check status of employee id "EMP001" Then response message should contain status as "Permanent" for employee id "EMP001"
Feature 2 Feature: Get Employee designation Scenario: Get employee designation as "System Consultant" Given database doesn't contain employee id "EMP001" And database is populated with employee id as "EMP001" and designation as "System Consultant" When employee status for "Permanent" is called to check status of employee id "EMP001" Then response message should contain designation as "System Consultant" for employee id "EMP001"
For the following step
When employee status for "Permanent" is called to check status of employee id "EMP001"
If a step definition is written to cater for both scenarios i.e. Contract (Step in Feature 1) and Permanent (Step in Feature 2) like this
@When("employee status for {string} is called to check status of employee id {string}")
public void employeeStatusForIsCalledToCheckStatusOfEmployeeId(String contractorOrPermi, String empId) {
if ("Permanent".equals(contractorOrPermi)
{
//Code to call Permanent Employee API
}else
{
//Code to call Contractor Employee API
}
}
Merging of steps like the above and not following SRP resulted in brittle BDD step definition code. Consider a scenario where the business wants to call Permanent Employee API for Apprentice. In order to cater that scenario, another if else statement needs to be introduced which in essence increases the opportunity to introduce bug in your step definition code
Static keywords in Step Definitions
One of the cardinal sin made at a very early stage of the project was the usage of static variables in java step definitions to share state. To make things worse, a java class which had static variables was used as a base class and all step definition classes extended this parent class. As the project grew, when BDDs took longer to run due to number of feature files, we couldn’t run them in parallel as we had state collision due to static variables. It also became very difficult to refactor, without doing a complete overhaul of the entire BDD framework.
Ignoring Best Practices
Since BDD step definitions are not part of the code that gets deployed in production, coding standards were ignored. The usual practice of running static code analysis, code review and auditing were ignored for step definitions. As a result the step definition code became difficult to manage and ended up having a fair amount of duplication. As the project grew, any changes to step definition became difficult and time consuming.
Not Failing Fast
While running BDDs it is important to get feedback immediately, particularly when you are running the entire suite. We made the mistake of not enabling an option to fail the entire BDD suite as soon as the first one failed. We waited for the entire suite to go through, which took more than an hour, before we identified the failed BDDs. Though this has an advantage of highlighting all the failed BDDs, it was taking more than an hour for us to find if the changes have impacted any of the business behaviors. By failing the suite as soon as the first one failed, we knew the changes did impact the business behavior and allowed us to take necessary action including reverting back our changes.
Not using the power of Regex
BDD steps use Regex to pass values to Step Definition. Regex is very powerful and at the same time it does require a steep learning curve. Understanding Regex is one of the key skills to rollout a good solution. Regex will help in reducing the number methods i.e. Step Definitions, avoid argument mismatch and reduce complexity. As you would expect none of our Test Engineers had strong Regex skills, and most, if not all, developers had exposure to Regex and none of them were expert. I believe this is a short coming of using product like Cucumber where it is heavily dependent on coding skills to automate.
Not using Tags
We ignored tagging features till it was required. The requirement came, when the time to run BDD suite became unacceptable, so we decided to differentiate Core and Non-Core features. Core features were run after every change made to development repository and Non-core were run during nightly build. Though adding tags to features is relatively a simple task, rolling it out required lot of “discussion” with Business and Management. Hindsight, if this had been adopted from day one and all stakeholders been updated then it would have been a much easier change
Summary
BDDs are fantastic and are a must-have for any project. I strongly believe that you are not Agile if you don’t use BDDs. It does offer the benefit it promises which is collaboration. However automating BDDs is not easy. It does require a strong design and a sound implementation and solid development principles. The tools supporting Automating BDDs are still evolving, till then careful consideration has to be given before you embark on automating BDDs or else you will end up with long-running, brittle automated test suite. Hopefully, you can avoid some of the expensive mistakes we made in our journey.
STAY IN THE LOOP
Subscribe to our free newsletter.
I am a huge fan of Toyota when it comes to process and lean manufacturing. They invented and brought in many of the lean production processes, which were then adopted by many other car manufacturing companies across the world. One of the key goals of the Toyota Production System (TPS) […]
Increase reusability of your Steps by using Parameters while rolling out Behavior Driven Development
One of the salient features in any Software Development is Reusability. Without reusability, maintainability and speed of implementation reduces drastically. Same applies when it comes to writing your Features in Behavior Driven Development. This blog explains, why reusability is important in Behavior Driven Development, how steps can be reused, what […]