by nocodebdd
Share
 We recently released a functionality called “continue on failure” in NoCodeBDD. This functionality is useful when you want to continue running a scenario even when a step fails. In this article, we will look at the reasoning behind this functionality and how and where it can be useful.
We recently released a functionality called “continue on failure” in NoCodeBDD. This functionality is useful when you want to continue running a scenario even when a step fails. In this article, we will look at the reasoning behind this functionality and how and where it can be useful.
When automating behavior-driven development (BDD) workflows, a fundamentally important aspect is to keep each scenario running independently, allowing for easier debugging and reducing maintainability. To keep scenarios independent, it is important to set up data at the beginning of the scenario and clear the data at the end of the scenario. This is quite a common approach in any automation test.
In this article, we will look at:
- How to set up and tear down data in BDD automation
- Use of hooks for setting up and tearing down data
- Issues with using hooks
- Benefits of NoCodeBDD’s “continue on failure” option
Scenario Independence
It is extremely important to ensure that test scenarios are not dependent on each other. This makes it easy to maintain and debug BDD test suites. Let’s look at the issue of creating dependent scenarios with an example.
Dependent Scenarios
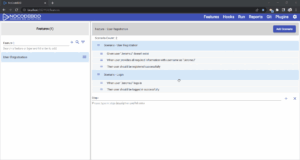
Let’s look at following two dependent scenarios: the second scenario, Login, is dependent on the User Registration scenario to set up a user account.
As you can see from the following gif, in order for the “Login” scenario to work, you need to run “User Registration” scenario. In other words, the “Login” scenario is dependent on the “User Registration” scenario.
Issues with dependent scenarios
When two BDD scenarios are dependent on each other, changing one impacts the other. In the following example, if the user registration is updated to have a different username, then the login scenario will fail, as shown below:
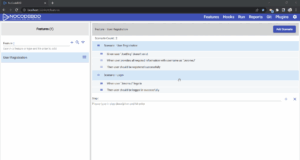
This seems to be easy to maintain, since we are looking at only two scenarios. Typically, in a project, you’re likely to have hundreds, if not thousands, of scenarios. Changing a scenario may impact many or all of the others if they are dependent. In a large project, this is extremely difficult to debug and identify issues when a scenario fails. And the dependency makes it difficult to maintain, as you’ll be unsure whether changing a scenario impacts other scenarios
Making Scenarios Independent
In order to make the above scenarios maintainable and easy to debug, all data setup should happen within the same scenario. In the above example, the Login scenario should be modified such that it is not dependent on user registration. In order to achieve that, the Login scenario could be modified to set up its own user data as shown below:
Scenario: Login Given user "JoeBlog" exists as a registered user When user "JoeBlog" logs in Then user should be logged in successfully
By having all steps that are required to execute the scenario, the scenario is independent of all other scenarios and could be run on its own. By creating this independent scenario, you can be sure any changes to other scenarios won’t impact this scenario, and vice-versa. Moreover, it will be easier to debug when this scenario fails, as any failure in this scenario is within the scenario and not not dependent on any other scenarios.
When setting up scenarios, it is quite important to set up the data before running the actual steps that checks the system, such as the Login process. It’s also important to clear the data after it executes to make sure the data setup doesn’t impact any other scenarios.
Setting up and clearing data
As we saw in previous section, to make scenarios independent, it’s crucial to set up all required data at the start of the scenario and clear those data and any other data that the scenario might have created after the scenario. If the data doesn’t get cleared, it can impact other scenarios. In the following demonstration, data is set up at the start of the scenario and cleared at the end:
Scenario: Login Given user "JoeBlog" exists as a registered When user "JoeBlog" logs in Then user should be logged in successfully And all data is cleared in database
Clearing of data can be quite common across all scenarios; for an example, you could create a step that clears all data in a database. One option is to keep repeating this step in every scenario, but this is not efficient. Another way to achieve clearing the data is by using Hooks. In NoCodeBDD, you can create “after hooks” and “before hooks”. Let’s take a look at these below.
Using Hooks
The following video demonstrates how you can easily create before and after hooks in NoCodeBDD through few clicks:
By using hooks, you can easily create a common step that is executed as an after hook and clear the data in the database, as shown below:
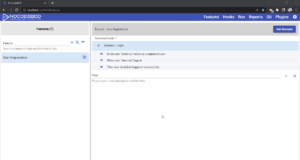
Clearing data on failure
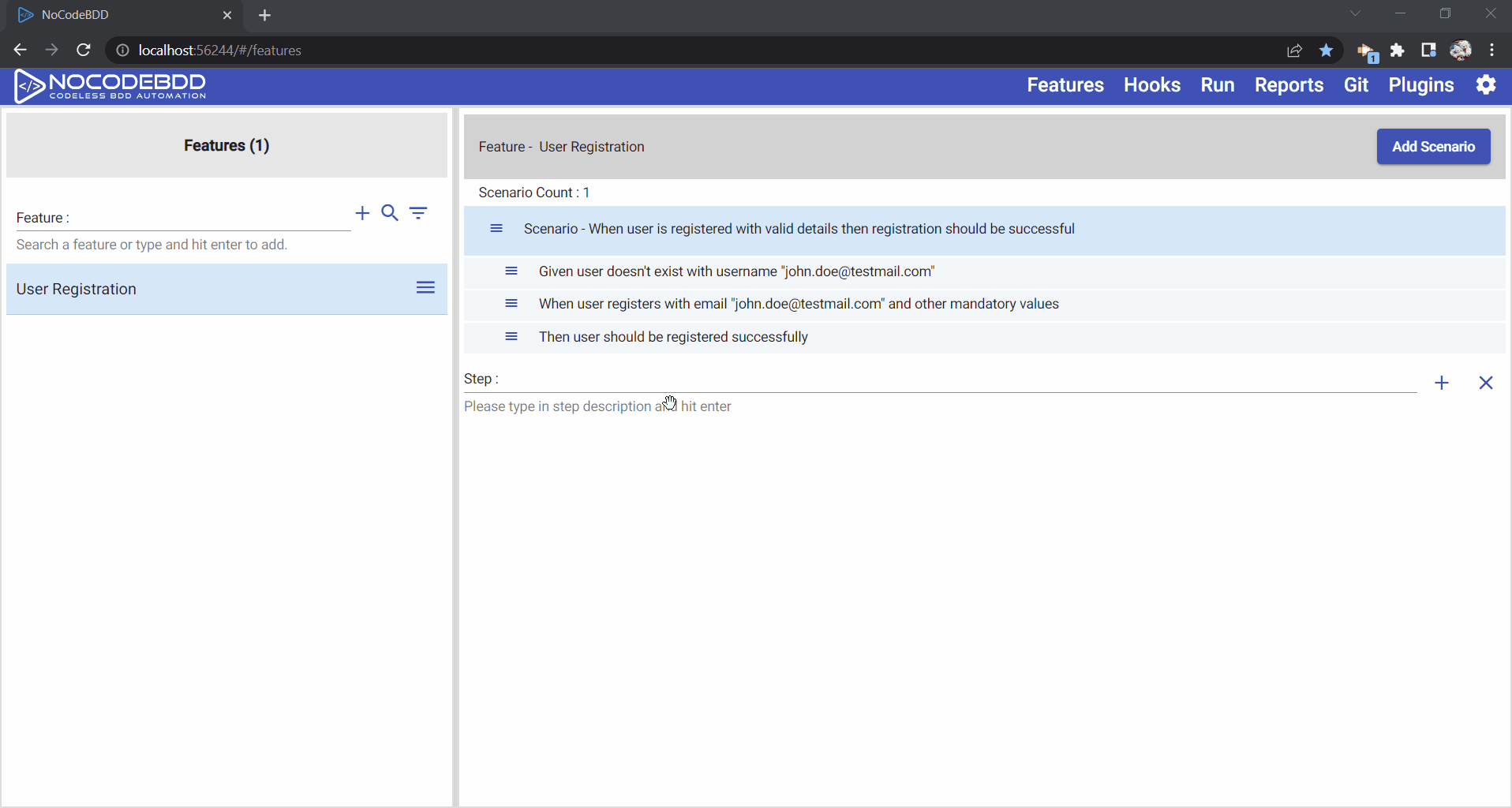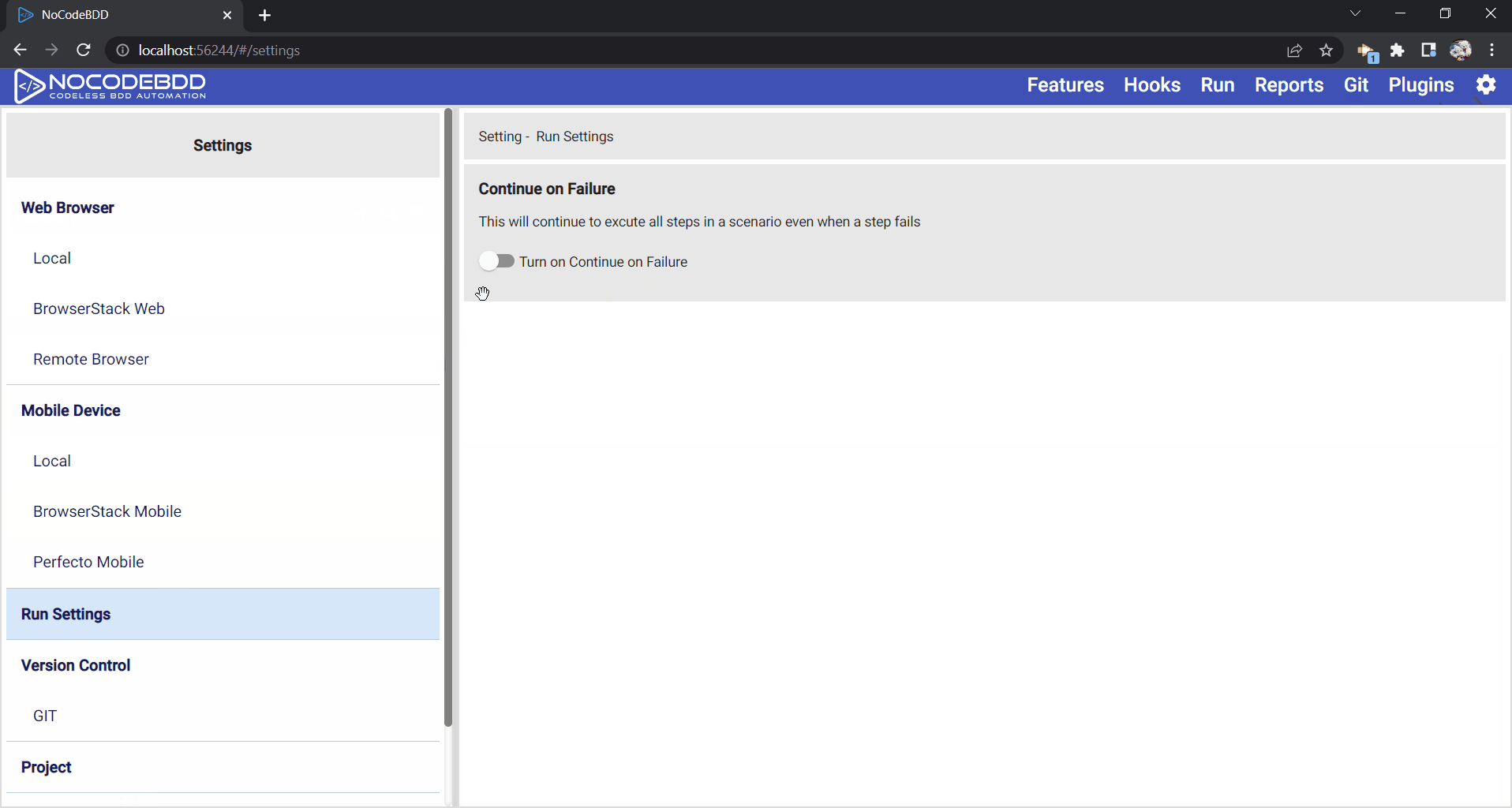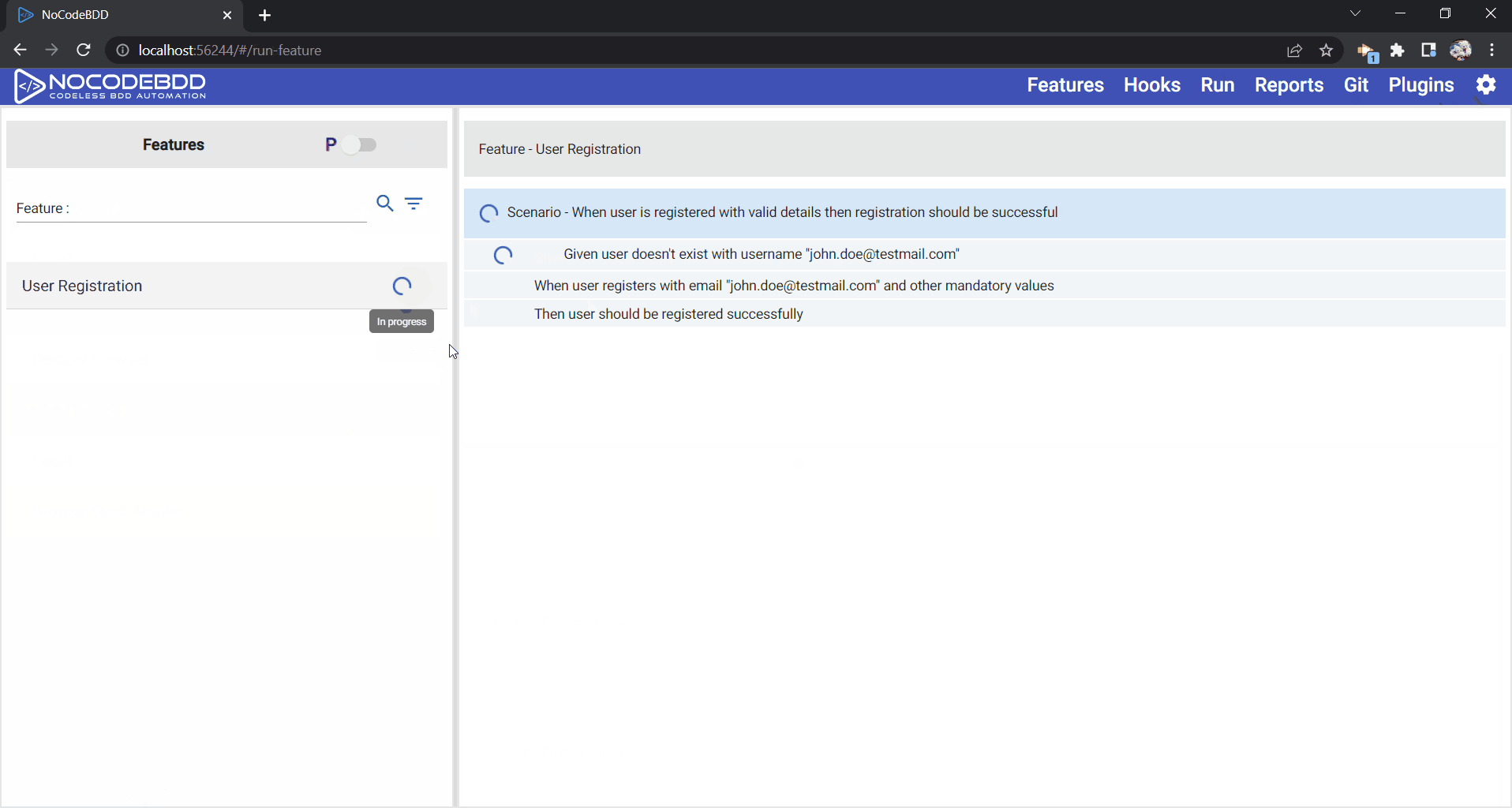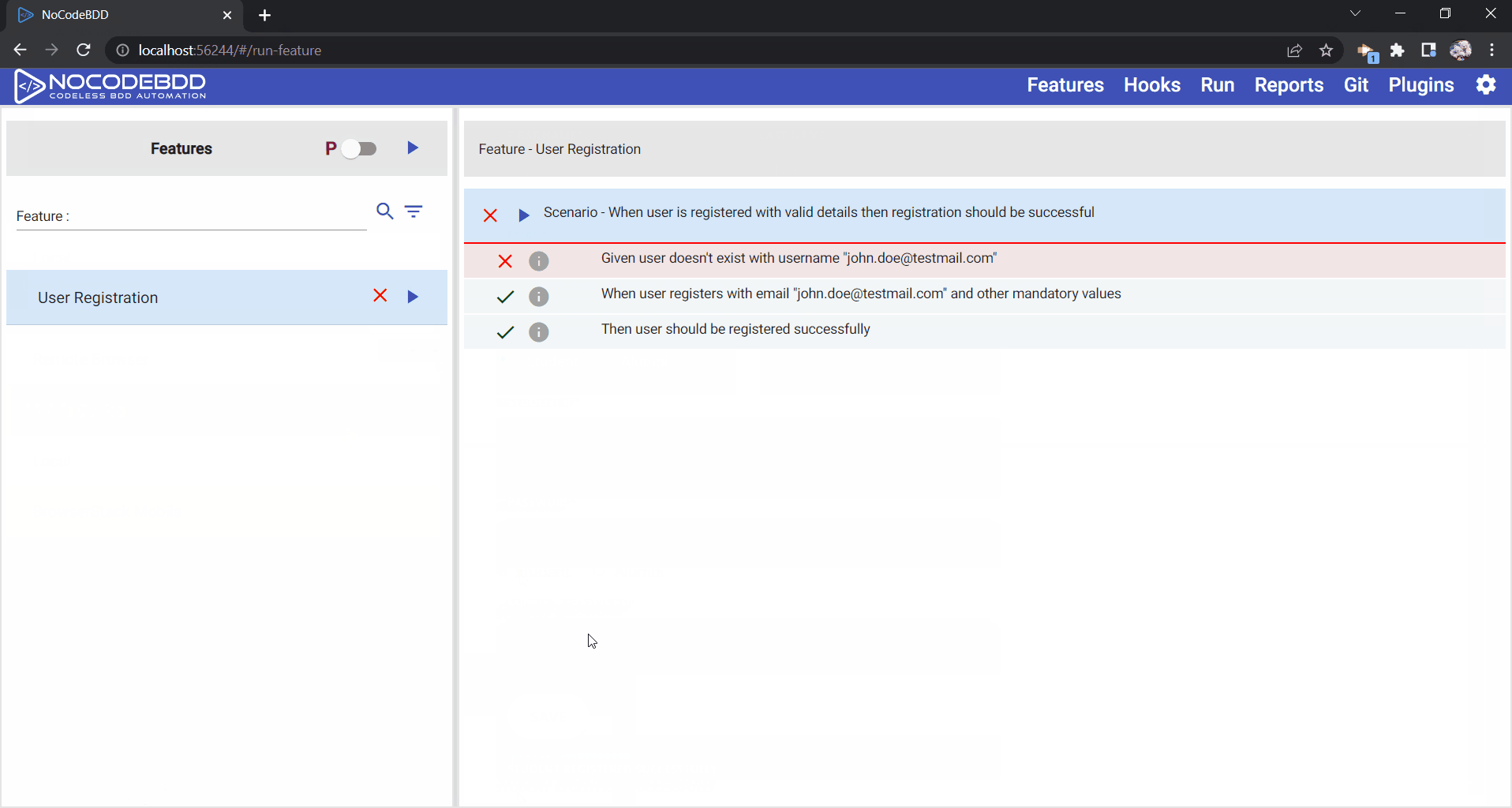
The most important point to note about hooks is that when a step in a scenario fails, all the steps, except hooks, following the failed steps will also fail. This is the default behavior in Cucumber and in NoCodeBDD. So, even if a step in a scenario fails, the hook will execute and clear all required data so that other scenarios continue to execute.
Hooks are great when you want to run a common step. However, this won’t work when you run features in parallel. Let’s look at why a common step to clear data won’t work when you run features in parallel in the following section.
Parallel Run
It is quite important to run features in parallel. We’ve actually written on this topic previously. The following article shows why considering parallel running from day one of your BDD automation project is important:
Issue in using hooks
Having a common step to clear data during a parallel run won’t work. That’s because when one of the scenarios is running and another scenario runs in parallel to it, some data that the other scenario is dependent on may get cleared. In order to avoid that, it is quite important to clear the data that is specific to the scenario, as shown below:
Scenario: Login Given user "JoeBlog" exists as a registered When user "JoeBlog" logs in Then user should be logged in successfully And "JoeBlog" is removed from database
When there are steps that are specific to a scenario, it is not efficient to use hooks. This is precisely the reason why we introduced the continue on failure option in NoCodeBDD. Let’s take a look.
Continue on failure
When a step fails, if the rest of the steps continue, then any data specific to that scenario will be lost. Thus, NoCodeBDD has an option called “continue on failure”, as shown below. By enabling this step, even when a step fails, the rest of the steps will continue, and the data for that particular scenario will be cleared. The following video shows how you can enable the continue on failure option and execute the login scenario successfully and clear the user “JoeBlog” even if one of the step fails.
STAY IN THE LOOP
Subscribe to our free newsletter.
Software testing frequently encounters sporadic problems, such network outages. Even if the application being tested is working properly, these problems can cause automated test scenarios to fail. We have created a new retry functionality that automatically retries failed BDD scenarios in order to solve this issue. In this blog post […]
I am a huge fan of Toyota when it comes to process and lean manufacturing. They invented and brought in many of the lean production processes, which were then adopted by many other car manufacturing companies across the world. One of the key goals of the Toyota Production System (TPS) […]
Increase reusability of your Steps by using Parameters while rolling out Behavior Driven Development
One of the salient features in any Software Development is Reusability. Without reusability, maintainability and speed of implementation reduces drastically. Same applies when it comes to writing your Features in Behavior Driven Development. This blog explains, why reusability is important in Behavior Driven Development, how steps can be reused, what […]
Recently I have been working in a large enterprise project, which uses Behavior Driven Development quite heavily. I have always been a huge admirer of BDD and the benefits it can bring to a project. I have personally experienced this in many projects where we have used BDDs. However, as […]